
Creating an index in SQL Server is a moderately simple task that improves the query performance. We can create a clustered as well as a non-clustered index which can be either unique or non-unique as per requirement.
If we have already created an index on a table, however, due to a requirement change, we need to add/remove one or more columns to an existing index. In this case, we can use the DROP_EXISTING option without writing the extra line of code to drop the existing index first and then re-create it. (This is an old fashioned coding style: Drop if Exists and Create a New.)
With DROP_EXISTING = ON, SQL Server will drop and rebuild the existing clustered/non-clustered index with modified index specifications, keeping the index name same as it exists. We can add/remove columns, modify the sort order, or change a filegroup as well.
DROP_EXISTING is by default OFF, and it does not work if you are including this option while creating a new index for the first time. DROP_EXISTING = ON in SQL Server only works if you already have an index with the specified name on a table.
With DROP_EXISTING, we can do the following:
1. Changing a Non-Clustered index to a Clustered index is permitted.
With DROP_EXISTING, we cannot do the following:
1. Changing a Clustered index to any other type of index is not permitted.
Advantages of Using DROP_EXISTING = ON
If we are re-creating a clustered index on a table, which already has a non-clustered index, using DROP_EXISTING = ON in SQL Server while re-creating a clustered index has the following benefits:
• Non-clustered indexes are not re-built again. If we are re-creating a clustered index with DROP_EXISTING = ON in SQL Server, it knows the clustering key has not been changed in the Non-clustered index. This saves a significant amount of time. Every Non-clustered index has a clustering key which refers to the Clustered index. If a clustered index is rebuilt, then SQL Server has to modify the Non-Clustered index as well. However, using DROP_EXISTING = ON is beneficial because we do not need to rebuild the Non-clustered indexes again.
• If we use the old method to drop and re-create a clustered index, it causes all non-clustered index on that table to be rebuilt again to match the clustering key. This can be saved using DROP_EXISTING = ON with clustered index.
Syntax for Index Creation with DROP_EXISTING
CREATE [Unique] [Clustered | NonClustered ] INDEX Index_Name ON <TableName> (Column Name/s) WITH DROP_EXISTING = { ON | OFF};
Examples
Create a sample table, Employee.
IF OBJECT_ID('Employee','U') IS NOT NULL DROP TABLE Employee; CREATE TABLE Employee ( Id INT PRIMARY KEY, Name VARCHAR(50), Telephone VARCHAR(10), Gender CHAR(1), Country VARCHAR(100), Salary DECIMAL (18,2) );
1. DROP_EXISTING = ON fails while creating a New Index
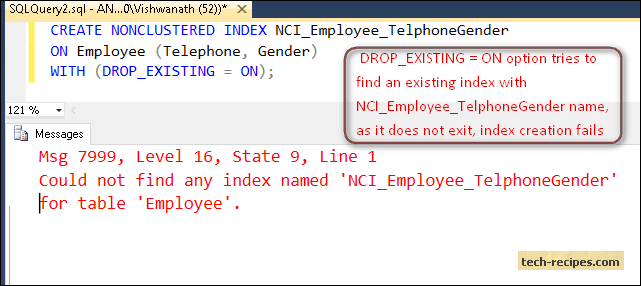
In the following example, the DROP_EXISTING = ON option tries to find an existing index with NCI_Employee_TelphoneGender name, as it does not exit, index creation fails with the following error message.
CREATE NONCLUSTERED INDEX NCI_Employee_TelphoneGender ON Employee (Telephone, Gender) WITH (DROP_EXISTING = ON);
Msg 7999, Level 16, State 9, Line 1
Could not find any index named ‘NCI_Employee_TelphoneGender’ for table ‘Employee’.
Creating an Index
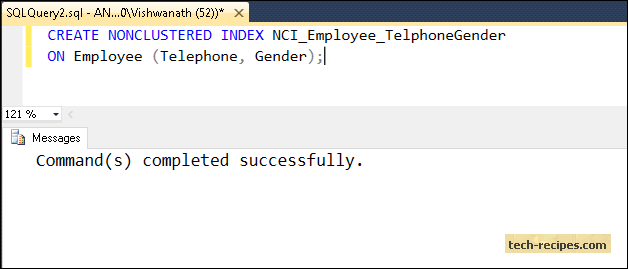
CREATE NONCLUSTERED INDEX NCI_Employee_TelphoneGender ON Employee (Telephone, Gender);
Query to See List of Columns in an Index
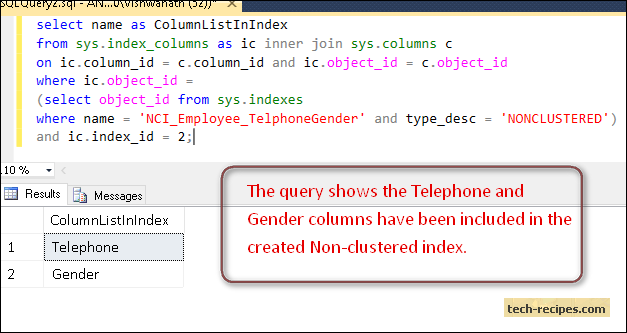
The query below shows the Telephone and Gender columns have been included in the created Non-clustered index.
select name as ColumnListInIndex from sys.index_columns as ic inner join sys.columns c on ic.column_id = c.column_id and ic.object_id = c.object_id where ic.object_id = (select object_id from sys.indexes where name = 'NCI_Employee_TelphoneGender' and type_desc = 'NONCLUSTERED') and ic.index_id = 2;
2. DROP_EXISTING = ON in SQL Server Works on the Existing Index
In the above example, we have created an INDEX, NCI_Employee_TelphoneGender on the Telephone and gender column. Now due to a change in the requirement, we need to include a Country column as well in the existing non-clustered index. We can achieve this using the DROP_EXISTING = ON option.
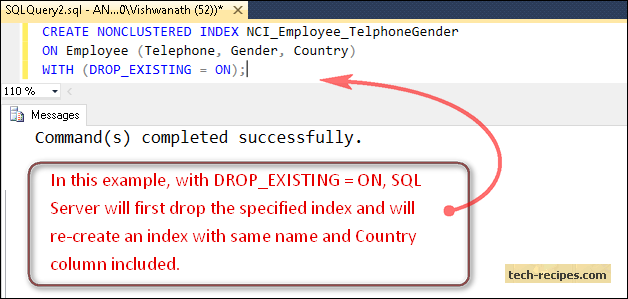
In the example below, with DROP_EXISTING = ON, SQL Server will first drop the specified index and will re-create an index with same name and Country column included.
CREATE NONCLUSTERED INDEX NCI_Employee_TelphoneGender ON Employee (Telephone, Gender, Country) WITH (DROP_EXISTING = ON);
Old Method for Writing the Code Above
The code above with DROP_EXISTING = ON is a replacement of an old method of dropping and re-creating an index. If we use the code below to drop/re-create clustered index, it will re-build all non-clustered indexes as well which could be a big performance hit.
IF EXISTS (SELECT * FROM sys.indexes AS si WHERE si.name = 'NCI_Employee_TelphoneGender') DROP INDEX NCI_Employee_TelphoneGender ON Employee; GO CREATE INDEX NCI_Employee_TelphoneGender ON Employee ( Telephone, Gender, Country ) GO
Summary
We have seen how DROP_EXISTING = ON in SQL Server helps us with clustered index to improve performance with few examples, and DROP_EXISTING = ON can only be used with existing created index in order to modify their specifications.


{kind=link}